




















Наконец-то, наконец-то начинается уже настоящая генетика!
Из предыдущих глав известно, что в структуре ДНК каким-то образом зашифрована структура протеинов и РНК, необходимых для жизни и развития живых организмов. С РНК все относительно понятно: и ДНК состоит из нуклеотидов, и РНК из них же (пусть немного отличающихся, но как-нибудь можно разобраться и сопоставить одни с другими). А как быть с построением белков? Нуклеотиды и аминокислоты сильно отличаются друг от друга, к тому же первых всего четыре вида, а вторых целых двадцать. Значит, нельзя просто одному нуклеотиду поставить в соответствие одну аминокислоту.
Нужен некий генетический код ( genetic code [ʤɪ’netɪk kəud] ), какие-то совершенно конкретные правила, по которым из четырех «букв»-нуклеотидов составляются «слова», которые каким-то образом считываются и переводятся в последовательность аминокислот, которая и является белком.
Ход мыслей генетиков, которые пытались разобраться в этом вопросе, был достаточно прост и предсказуем — ну по крайней мере сейчас так кажется:)
1. ДНК состоит из длинного, очень длинного набора нуклеотидов, которых насчитывается 4 вида — аденин, гуанин, цитозин и тимин (A, G, C, T).
2. Протеины построены из аминокислот, которых в земных организмах насчитывается 20 видов.
3. Каким-то образом между ними есть совершенно точное соответствие.
Мы знаем, что есть компьютерный код, устроенный таким образом, что определенная совокупность нулей и единиц обозначают конкретную букву. Так может быть и здесь та же схема? То есть какая-то конкретная последовательность нуклеотидов обозначает какую-то определенную аминокислоту? И если это так, то должен существовать какой-то непонятный клеточный механизм, который каким-то непонятным образом понимает, с какого места надо начинать считывать последовательность нуклеотидов для постройки нужного протеина? Да, ДНК невероятно длинная, нельзя же ее всю целиком считывать, нужно найти определенное место, где начинается ген. Потом он каким-то непонятным образом должен разворачивать в этом месте спираль ДНК? А потом он непонятно как должен разделять ее в этом месте на две нити и считать информацию? А потом непонятно как сшить нити ДНК обратно? И уже потом он каким-то опять же непонятным образом должен переносить эту информацию куда-то туда, где каким-то непонятным образом будет создаваться определенная аминокислота? И кроме того — кто этот «он», кто делает все эти явно непростые процессы? Значит здесь целая совокупность механизмов, обслуживаемая целыми толпами высокоспециализированных протеинов?…
Выглядит чертовски сложно, но другая логика здесь просто вообще не прослеживается. Есть набор нуклеотидов. Есть набор аминокислот. Между ними непременно должна быть какая-то логическая связь. Да, тут столько всяких «непонятно как», но другого варианта просто не видно. Поэтому генетики последовали заветам Шерлока Холмса, который отбрасывал невозможные версии до тех пор, пока не останется одна, возможная, и поэтому верная. Они решили, что скорее всего, всё устроено именно так сложно, и нужно просто начать внимательно изучать ДНК и искать ответы на все эти вопросы. И их усилия увенчались успехом, всё в самом деле оказалось именно так. Впрочем, не совсем. Все оказалось устроено не просто сложно, а очень сложно, настолько чертовски сложно, что и сейчас генетика находится только в самом начале своего длинного пути.
Зная, что ДНК состоит всего из 4 видов нуклеотидов, а протеины строятся из 20 аминокислот, легко догадаться, что не может быть такого, чтобы одной аминокислоте соответствовал один нуклеотид. Значит не может одна «буква» ДНК кодировать одну аминокислоту. А две? Допустим, если подряд стоят аденин и цитозин (AC), то это обозначает одну аминокислоту. Может так? Нужно подсчитать — сколько комбинаций мы можем составить из 4-х нуклеотидных букв: AA, AG, AC, AT, GG, GC, GT, CC, CT, TT. Всё. Восемь штук. Не 20. А вдруг клеточные механизмы способны различать AG и GA? Не поможет. Всё равно никак не 20. Ладно… А если комбинировать их по три штуки? Ну, тогда получается аж 64 комбинации. Неужели природа создала такую избыточность вариантов, зачем? Впрочем, другого варианта нет, значит так?
Оказалось именно так. Именно трёхбуквенным оказался один кодон ( codon [‘kəʊdɒn] ) — группа нуклеотидов, кодирующих какую-то аминокислоту. А избыточность количества разных кодонов оказалась очень полезным изобретением природы, что мы увидим ниже.
Итак, при расшифровке генетического кода получалось, что три подряд идущих нуклеотида в ДНК кодируют одну аминокислоту. Тут у расшифровывающих код ученых возникли сомнения: если все в самом деле устроено именно так, то генетический код оказывается слишком уязвимым! При возникновении любой, минимальной мутации, или при любой, единичной ошибке при снятии информации с ДНК, становится дефектной вообще вся последовательность нуклеотидов, шифрующая некий белок. Как именно? Давай разберемся.
Ген — это участок ДНК, т.е. такая последовательность кодонов, которая кодирует какой-то протеин или РНК. Поскольку каждой аминокислоте белка соответствует три нуклеотида в гене, значит этих нуклеотидов в гене должно быть минимум в три раза больше, чем аминокислот в белке, который строится по этому гену. На самом деле, нуклеотидов в гене еще больше, потому что в нем есть участки, которые не используются для построения белка.
Возьмем некий ген дикого типа — так называют совершенно правильные, не мутировавшие гены, которые успешно выполняют свою работу. Допустим для простоты, что этот исходный ген состоит из последовательности нуклеотидов с азотистыми основаниями C-G-A, многократно повторенными: C-G-A-C-G-A-C-G-A и т.д.
Теперь с этого гена согласно принципу комплементарности строится зеркальный слепок, отпечаток в виде так называемой матричной РНК. Зачем появляется какая-то дополнительная ступень в виде матричной РНК? Почему вместо того, чтобы взять молекулу ДНК и по ней построить протеин, сначала ее куда-то копируют? Потому что ДНК — это главная ценность клетки, которую необходимо оберегать от повреждений любой ценой. И если вокруг молекул ДНК будут постоянно находиться строящие протеины штуковины, считывая гены огромное количество раз (пока не будет произведено нужное клетке количество протеинов), риск повреждения генома возрастает многократно. В общем, строить протеины, непосредственно считывая ДНК — это все равно что имея единственную копию драгоценного фолианта с чертежами отдать его толпе жаждущих студентов.
Поэтому с молекулы ДНК снимается копия (матричная РНК), которая уже отдается на многократное прочитывание для построения по ней протеинов. Как это копирование происходит: напротив цитозина, находящегося в ДНК, встает гуанин строящейся молекулы РНК. Ни с чем другим цитозин не может образовать «ступеньку» вследствие принципа комплементарности. Затем напротив гуанина встает цитозин, ведь напротив цитозина может встать только гуанин. Затем напротив аденина встает урацил.. да, именно урацил, а не тимин. Потому что строится именно РНК-нить, а не ДНК, и именно урацил в ней заменяет типичный для ДНК тимин. И так далее. В результате напротив части гена «C-G-A» появился кусок РНК: «G-C-U», комплементарный ему. И дальше так и строится нить РНК параллельно нити ДНК. Значит если в гене есть цепочка C-G-A, то в матричной РНК эта часть гена будет выглядеть в виде G-C-U, поэтому я и называю этот слепок «зеркальным».

Вернемся к нашему скучному дикому гену, состоящему из повторов CGA. Его генный слепок состоит из совершенно одинаковых кодонов GCU, то есть идет многократный повтор одного и того же генетического «слова», которое обозначает аминокислоту аланин. И значит протеин, который будет построен по исходному гену, будет состоять из длинной цепочки аланинов. Значит генный слепок выглядит так: GCUGCUGCUGCUGCUGCUGCUGCUGCU. Соответствующая ему аминокислота выглядит так: Ala-Ala-Ala-Ala-Ala-Ala-Ala-Ala-Ala — ты видишь эту сосиску на верхней части картинки.
Теперь представим себе, что в гене случилась мутация, и нуклеотид тимин неожиданно влез в цепочку. Такая мутация называется «инсерцией» ( insertion [ɪn’sɜːʃ(ə)n] ). Значит в матричной РНК в нашу последовательность влезет нуклеотид, комплементарный тимину — аденин (А). В результате в последовательности аминокислот появился серин, которого там вообще не должно было быть! Но это только начало… В результате нахального вторжения оказался испорчен не только самый первый кодон, но и все последующие (это видно на средней части картинки): ведь механизм считывания информации теперь вместо GCU начнет считывать UGC. А этой последовательности соответствует не аланин, а цистеин.
Построенный мутантный протеин, в которой вместо цепочки аланинов зачем-то будет цепочка цистеинов, будет совершенно бесполезен, а может и вреден:
* В клетке появятся эти самые мутантные протеины — штуки, которые ни для чего не нужны и только мешают, занимая место и тратя клеточные ресурсы на их создание.
* Тут ты можешь вспомнить то, что раньше читала в этом учебнике (или в какой-нибудь генетико-книжке) и завопить: в каждой клетке ведь есть два комплекта хромосом! И даже если на одной из них ген мутировал и по нему начала производиться ненужная фигня, на второй ведь этот ген в целости и сохранности. Вот пусть парная хромосома и отдувается за двоих. Но все не так просто: производимого всего лишь по одной копии гена нормального протеина будет меньше, чем в случае двух таких копий. А в некоторых случаях ген может считываться только с одной хромосомы из пары, будучи заблокирован на другой. А у некоторых вообще только одна копия Х-хромосомы, так что если именно на ней будет поврежденный ген, то другую его копию взять неоткуда.
В общем, инсерция — это и в самом деле серьезная, опасная мутация несмотря на то, что существуют и внутриклеточные механизмы коррекции мутаций, и двойной комплект хромосом в каждой клетке.
То же самое происходит при другой неприятной мутации — делеции ( deletion [dɪ’liːʃ(ə)n] ) (на той же картинке внизу): из гена выпадает цитозин (С), значит из матричной РНК выпадет соответствующий ему гуанин (G), и вместо кодонов GCU, кодирующих аланин, появляются кодоны CUG, и начинает производиться аминокислота лейцин. Вроде бы процесс обратный: вместо вставки лишнего нуклеотида вывалился один нужный, а результат — в той же степени плохой.
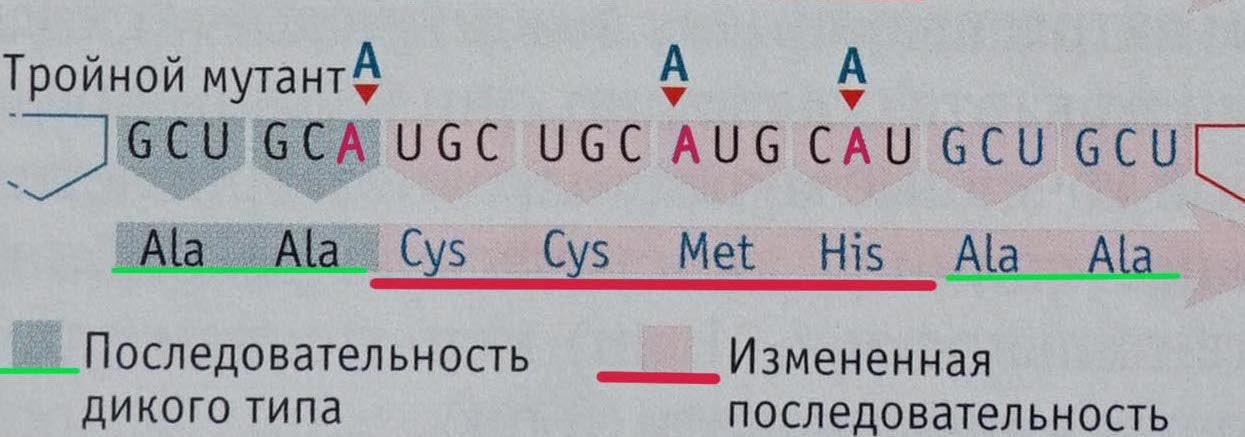
При исследовании инсерций и делеций была обнаружена любопытная штука: если сделать три инсерции, или три делеции в середине какого-то гена, то построенный протеин будет совершенно нормален, правилен в своем начале и конце, и только в том месте, где сделаны три мутации, протеин построился неправильно. Это иллюстрируется схемой справа. Мы последовательно вставили три лишних нуклеотида тимина «T» в ген, чем попортили эту его часть. В матричной РНК соответственно появляются три лишних нуклеотида аденин (А). Но все, что идет правее этих вставок, просто сдвинулось ровно на 3 нуклеотида, а значит — совершенно не изменилось, и если в середине построенного по этой схеме протеина будут находиться неправильные аминокислоты, то слева и справа от них протеин будет выглядеть совершенно нормальным. Возможно, он даже сможет вполне нормально выполнять свои функции. Такие эксперименты доказали, что кодон в самом деле является триплетным ( triplet[‘trɪplət] ): состоит именно из трех букв-нуклеотидов. То есть именно три нуклеотида являются одним генетическим «словом», означающим ту или иную аминокислоту.
После доказательства триплетности кодона встал вопрос: каким образом целых 64 возможных комбинации из трех нуклеотидов могут кодировать всего 20 аминокислот? Оказалось, что несколько кодонов могут обозначать одну и ту же аминокислоту, а 3 кодона и вовсе никаких аминокислот не кодируют, а дают определенные сигналы. Тот механизм, тот протеиновый комплекс, который занимается считыванием информации с гена, эти сигналы умеет понимать. Сигнал, который сообщает, что в данном месте ген закончен и считывать больше ничего не нужно, называется стоп-кодон ( stop sign [stɔp saɪn] ).
Ниже мы видим великую таблицу жизни — генетический код, открытие которого стало настоящей вехой, настоящим спусковым крючком для бурного развития генетики.
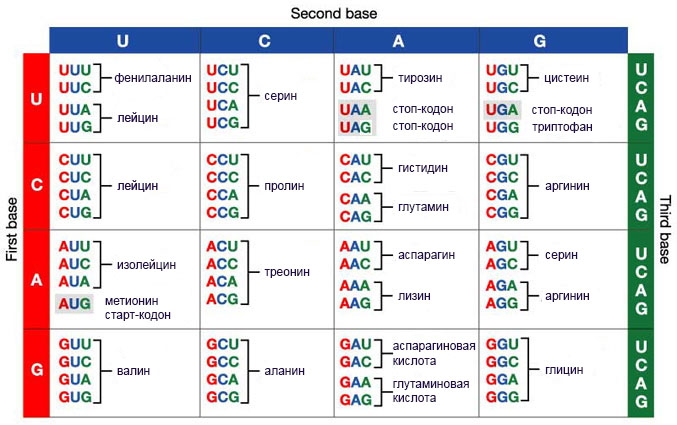
Благодаря тому, что все живые существа Земли используют именно его, возможен обмен генами между разными видами. Можно поместить ДНК одного существа в клетку другого, и она будет успешно прочитана, и по ней начнется производство совершенно конкретных протеинов или РНК. Так поступают бактерии, обменивающиеся друг с другом генами в процессе горизонтального переноса. Так поступают вирусы, впрыскивая свою ДНК в клетку другого организма. Единство генетического языка приводит к тому, что жизнь на Земле пребывает в состоянии удивительной гармонии (исключая некоторые вещи и явления, сделанные не самыми лучшими представителями рода человеческого).
Из таблицы видно, что некоторые аминокислоты кодируются двумя, другие — четырьмя или даже шестью кодонами, и лишь одна аминокислота — триптофан — кодируется всего лишь одним кодоном. Такое распределение кодонов не случайно, иначе естественный отбор давно бы его уничтожил. Вообще каждый раз, когда тебе кажется какое-то свойство живого существа непонятно-нелепым, стоит вспоминать, что эволюция не терпит «излишеств»: то, что не приносит каким-нибудь неочевидным образом пользы организму или целому виду, надолго не задерживается. Причины избыточности генетического кода в этой главе рассматривать не стоит, достаточно знать, что они есть.
Часто кодоны, обозначающие одну и ту же аминокислоту, отличаются только последней буквой. Есть предположение, что это отпечаток древнейшей истории: самые первые живые существа были гораздо более примитивными, чем самые простейшие из существующих на данный момент, и обходились гораздо меньшим количеством аминокислот в своих клетках. Так что им вполне хватало двухбуквенного кода, составленного из тех же четырех нуклеотидов. Но потом оказалось, что в окружающем этих существ бульоне есть еще кое-какие полезные штуки, которые неплохо бы применить в хозяйстве. Чтобы использовать все доступные и полезные аминокислоты, двухбуквенного кода уже не хватало, и нашим далеким предкам пришлось пожертвовать скрепами и перейти на новый алфавит.
Этих знаний о генетическом коде достаточно для того, чтоб на самом поверхностном уровне рассмотреть механизм его чтения и создания протеинов.
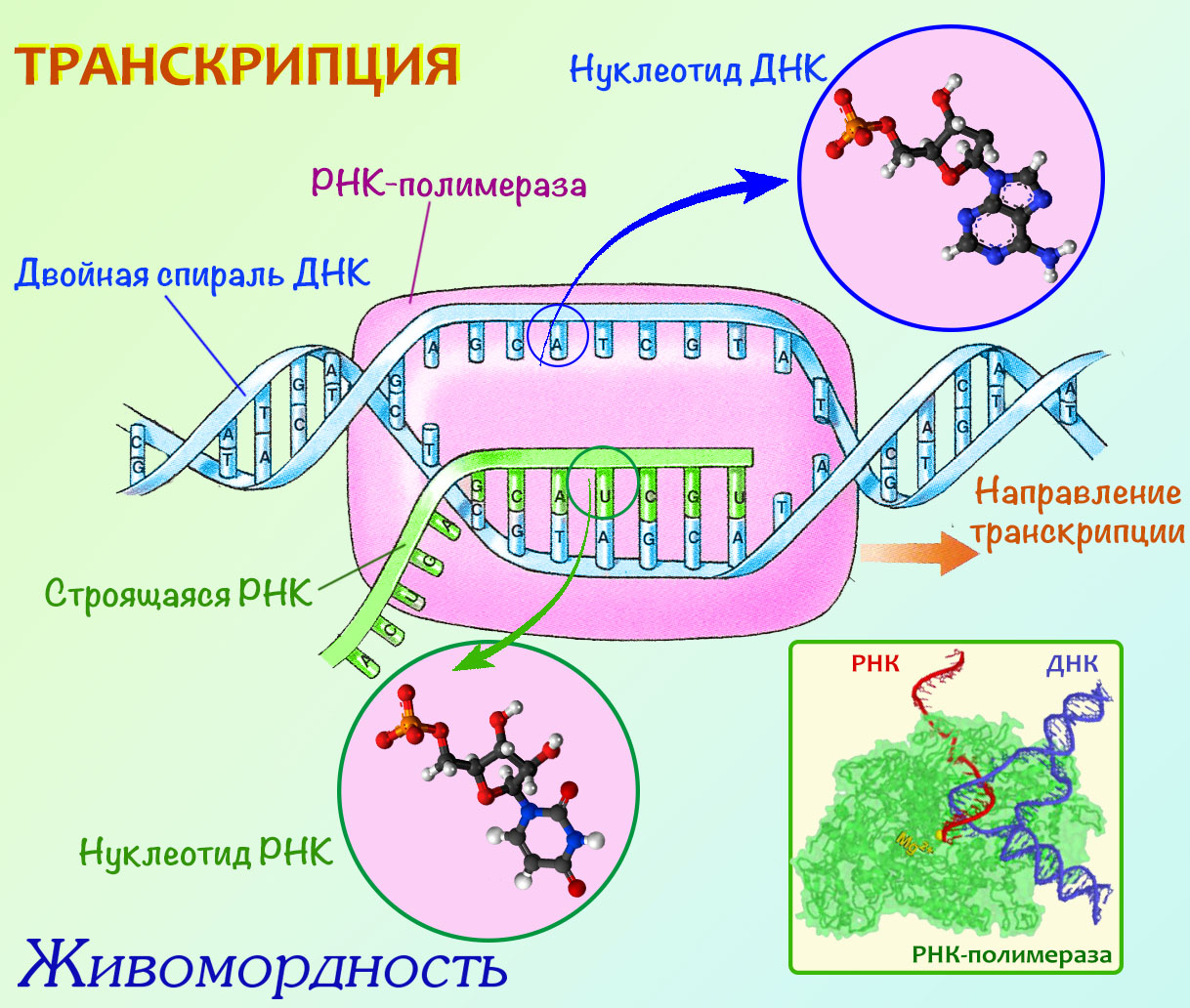
Из главы 13 уже известно, что транскрипцией, то есть чтением цепочки ДНК занимается сложный протеиновый комплекс РНК-полимераза (на английском она имеет и второе обозначение, соответствующее русскому: RNA-polymerase [ɑːr-en-eɪ pə’lɪməreɪz] ). Теперь посмотрим — каковы этапы её работы. Справа иллюстрирующая картинка — посматривай на неё в процессе чтения, и будет яснее.
1. Сначала РНК-полимераза находит начало нужного ей гена.
2. Затем она разъединяет двойную спираль ДНК в этом месте, чтобы отдельная нить ДНК стала доступной для считывания.
3. Теперь начинается филигранная работа: к каждому нуклеотиду выбранного гена РНК-полимераза подбирает комплементарный ему нуклеотид, соединяя их один за другим в цепочку рождающейся таким образом РНК: напротив «A» ставится «U» (не забываем, что в цепи РНК вместо тимина используется урацил, очень похожий на него и с таким же удовольствием спаривающийся именно с аденином), напротив «C» ставится «G». Таким образом, РНК-полимераза создаёт новую РНК, комплементарную гену — своего рода слепок гена, но не в точности как ген, а комплементарный ему. Можно привести такую аналогию: если мы хотим сделать скульптуру кошки, то сначала мы можем сделать гипсовый слепок с неё. Каждой выпуклости на теле кошки в нашем слепке будет соответствовать вогнутость, и наоборот. А затем в этот слепок мы зальем бронзу, и получим искомую скульптуру. Бронзовая скульптура будет в свою очередь «комплементарна» слепку — там где на слепке выпуклость, в бронзе будет вогнутость. РНК-полимераза строит именно такие «комплементарные слепки» с гена.
Поскольку построенная РНК становится своего рода слепком с ДНК, или, иначе говоря, матрицей, по которой в дальнейшем будет строиться протеин, то она называется матричной РНК, или мРНК.
Итак, РНК-полимераза строит мРНК, которая является комплементарным слепком с гена.
Почему РНК-полимераза строит именно РНК, а не ДНК? Почему эволюция выбрала именно такой способ переноса информации, создав для этого дополнительный нуклеотид урацил? Я думаю, что это вполне логично. Когда у нас есть что-то ценное, то мы хотим, чтобы оно отличалось от всякой ерунды даже внешне, даже по своей упаковке, чтобы случайно это очень ценное не выкинуть, не повредить. И тем более, если у нас есть множество протеиновых механизмов, которые создают мРНК, потом переносят ее туда, где будет строиться протеин, потом работают с ней, создавая протеин, то вполне логично, если мы захотим уберечься от случайностей, чтобы вся эта армия рабочих случайно не повредила ДНК. ДНК — ценнейший объект в клетке. Если случайно будет повреждена какая-то митохондрия, так и черт с ней, проживем и без нее. Если сломается микротрубочка или лизосома — и черт с ними. Но ДНК! ДНК должна храниться так, чтобы никто даже случайно не мог ее повредить. Поэтому и есть урацил. Поэтому слепок с ДНК очень сильно (с точки зрения клеточных механизмов) отличается от ДНК, и даже если кто-то из рабочих, имеющих дело с РНК, приблизится к ДНК, то он ничего с ней не сможет сделать — она другая, он не умеет ничего с ней делать. В этом я вижу смысл того, что мы имеем именно матричную РНК, а не матричную ДНК, и создание для этой цели урацила совершенно оправдано.
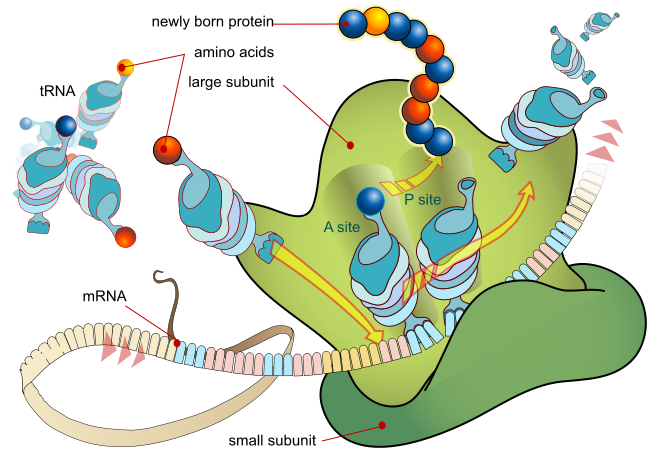
4. Теперь мРНК переносится из ядра в основное тело клетки и попадает в лапы еще более сложного, совершенно уникального комплекса под названием «рибосома«, состоящей из протеинов и молекул РНК. Справа мы видим очень, очень упрощенную её схему. Задача рибосомы — по слепку с гена теперь построить протеин. Именно тут осуществляется завершающий этап всей этой цепочки процессов, начинающейся с кажущегося абракадаброй набора нуклеотидов, и кончающейся реальным протеином, состоящим из последовательности аминокислот.
На этом рисунке видно, что рибосома состоит из двух субъединиц: большой (вверху салатового цвета) и малой (темно-зеленая внизу). Сначала малая субъединица приплывает и фиксируется с одной стороны мРНК, затем подплывает большая и накладывается с другой стороны, и таким образом матричная РНК оказывается зажатой между ними.

В цитоплазме клетки во множестве плавают так называемые транспортные РНК ( transfer RNA [træns’fɜː ɑːr-en-eɪ] ) или, короче, тРНК ( tRNA [ti ɑːr-en-eɪ] ). На рисунке выше они видны — такие голубые составные бочонки. Мы помним, что любая РНК состоит из последовательности нуклеотидов 4-х видов, поэтому на рисунке они и изображены состоящими из голубых элементов четырех оттенков.
А слева ты можешь посмотреть на тРНК крупным планом — как она выглядит в 3-хмерной своей обычной форме, и как — в плоском, развернутом виде (похожа на лепесток клевера), но подробнее разбирать ее структуру мы в этой главе не будем.
Каждая тРНК на одном своем конце имеет одну, совершенно конкретную аминокислоту, изображенную в виде цветного шарика на верхнем рисунке. Каждой аминокислоте соответствует своя собственная тРНК. Та тРНК, которой предназначено подцепить, скажем, триптофан, никогда не подцепит глицин. Так что мы имеем много разновидностей тРНК.
Именно тРНК приносят в рибосому аминокислоты, из которых строится протеин. Таким образом рибосома является фабрикой по постройке протеинов. мРНК является чертежом, который притаскивают к рибосоме. тРНК являются поставщиками стройматериалов — аминокислот.
Осталось разобраться в том — как же именно теперь возникает новый протеин? Как именно работает рибосома?
На картинке мы видим цепочку разноцветных шариков. Это и есть создающийся протеин. Мы застали рибосому в тот момент, когда она собирается прицепить еще одну аминокислоту к уже созданной части протеина.
Обрати внимание, что каждая тРНК на своем другом конце имеет свой собственный триплет нуклеотидов. Он называется антикодон ( anticodon [ˌantɪ’kəʊdɒn] ). Рибосома, удерживая мРНК зажатой между своими субъединицами, выставляет наружу один из её триплетов. Подплывая к зажатой в рибосоме мРНК, тРНК тыкается в этот выставленный триплет своим антикодоном. Если комплементарности нет, то тРНК не скандалит и не требует обслуживания вне очереди, а тихо и дисциплинированно отплывает в сторонку и либо ищет соседнюю рибосому — может там подошла ее очередь — либо тусуется тут же дальше, ожидая своей очереди. На схеме вся тусовка ждущих своей очереди тРНК изображена слева.
Рано или поздно подплывает именно та тРНК, антикодон которой комплементарен выставленному наружу триплету мРНК, и тогда тРНК прицепляется антикодоном к этому триплету. После этого весь рибосомный конвейер приходит в движение:
а) тРНК захватывается рибосомой (нежно, конечно, но крепко), и удерживается на своем месте (на картинке это место обозначено как «A-site» (от слова «accept», «принимать»).
б) Рибосома переезжает по мРНК на три нуклеотида влево, при этом та тРНК, которая стояла на позиции «P-site» (от слова «peptide», «пептид», т.е. «совокупность аминокислот), переезжает еще правее, попадает на «E-site» (от слова «exit», «выход»), не обозначенный на картинке, и после этого выпускается на свободу — заново искать свою аминокислоту взамен той, что она отдала рибосоме
в) Только что присоединившаяся тРНК теперь оказывается на позиции «P-site». В этой позиции на принесенную ею аминокислоту аккуратно насаживается сверху уже созданная часть протеина. В это же самое время новые тРНК тыкаются своими антикодонами в уже следующий триплет мРНК, который рибосома предлагает для стыковки.
Дальше все движется аналогично, и наконец рибосома доезжает или до конца мРНК, или до стоп-кодона (ведь одна мРНК может нести информацию о разных протеинах). После этого работа рибосомы завершается, строительство протеина закончено и он передается дальше для последующей обработки и транспортировки уже другими клеточными механизмами, а рибосоме пора снова разделяться на большую и малую субъединицы и захватывать следующую мРНК и продолжать свою работу. В общем, ничего сложного, если взглянуть на этот процесс вот так, издалека. Но при ближайшем рассмотрении все описанные механизмы представляют собою сложнейшие комплексы биохимическх реакций. И чем детальнее генетики смогут в этих реакциях разобраться, тем легче им вносить те или иные коррективы. Например, можно что-то такое точечно сломать, чтобы прекратить выработку какого-то ненужного протеина. Или наоборот, что-то починить при необходимости.
Процесс, в результате которого по чертежу-мРНК строится протеин, называется трансляцией ( translation [trænz’leɪʃən] ). Процесс снятия информации с гена называется, как мы помним, транскрипцией. Таким образом весь процесс построения протеина по карте ДНК состоит из двух больших подпроцессов — транскрипции и трансляции, и в них участвуют ген, мРНК, тРНК и рибосома, и еще много других участников, которые мы тут не стали рассматривать и которые обеспечивают работу указанных выше процессов.
Ролики с анимацией вышеописанных процессов можно посмотреть тут (англ.) и тут (русск.)
Впрочем, в школах России дети получают гораздо более полезную информацию…